Table of contents
Open Table of contents
Objective
To focus on the performance of the latest binlog, Quill, and fmtlog libraries on common data (string, double, complex structures, etc.).
Methods of Comparison
There are two methods:
- Method 1: Warm up a certain number of times compare to say 10,000 times and then for loop 100,000 times, and then divide the total time by 100,000. However, this method fully utilizes the cache, and it is only a lower limit of the ideal delay situation, which does not match the actual situation.
- Method 2: Record the time difference each time, and then add up the 100,000 times. Note that you need to insert some meaningless operations between each time to simulate a real caching scenario. (poison L1 cache)
All of the following results are from tests run on a kernel-isolated machine with kernel tethering.
Single-thread results
log one Foo struct (char data[200] + int64_t + double):
result of Method 1:
| Library/Quantile Time (ns) | 0th | 50th | 75th | 90th | 95th | 99th | 99.999th | 100th |
|---|---|---|---|---|---|---|---|---|
| Quill | 19 | 29 | 29 | 29 | 49 | 79 | 759 | 949 |
| fmtlog | 19 | 19 | 29 | 29 | 29 | 29 | 1479 | 1949 |
| binlog | 29 | 29 | 39 | 39 | 39 | 39 | 102267 | 104247 |
result of Method 2:
| Library/Quantile Time (ns) | 0th | 50th | 75th | 90th | 95th | 99th | 99.999th | 100th |
|---|---|---|---|---|---|---|---|---|
| Quill | 99 | 109 | 119 | 159 | 229 | 389 | 2489 | 2599 |
| fmtlog | 30 | 40 | 40 | 40 | 40 | 110 | 3290 | 456198 |
| binlog | 39 | 49 | 49 | 59 | 59 | 69 | 117157 | 117737 |
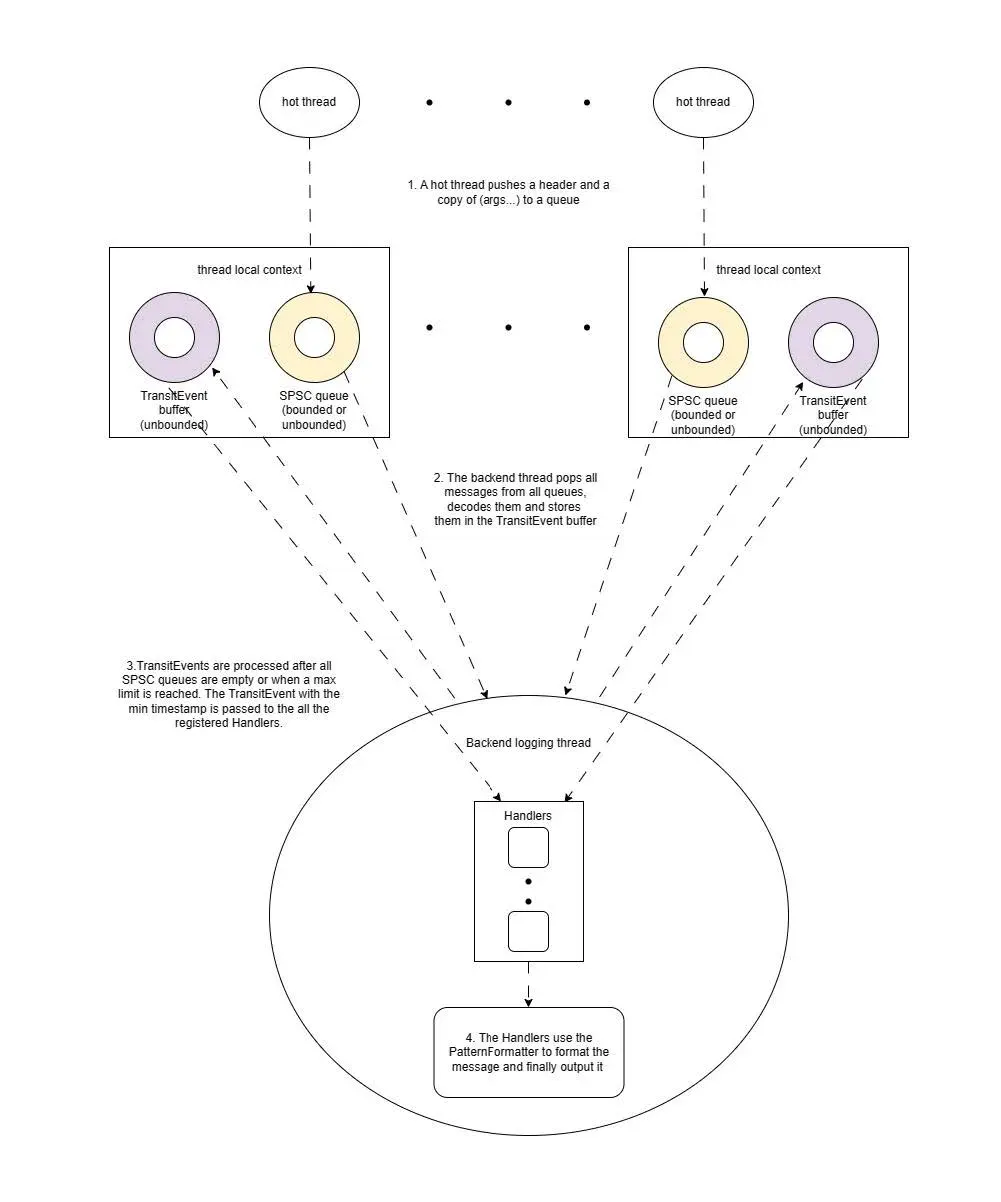
Note that in order to optimize Quill’s speed, I went ahead and changed the defaut_queue_capacity of the config to 67108864 (64MB), to prevent the need to create a new SPSC queue while keeping it running (since Quill internally has a thread_local SPSC queue for each thread, and the logger’s background queue pops out of each thread’s SPSC queue and writes files to it). (Because Quill has a thread_local SPSC queue for each thread, and then the logger’s backend queue pops out of each thread’s SPSC queue and writes to the file), as does fmtlog.
In method two, I create a volatile char array and rewrite the size of the L1 cache over and over again, which is equivalent to inserting a poison L1 cache operation in between each time.
Multi-thread results
Multi-thread results are all in Method 2.
4-thread results:
| Library/Quantile Time (ns) | 0th | 50th | 75th | 90th | 95th | 99th | 99.999th | 100th |
|---|---|---|---|---|---|---|---|---|
| Quill | 30 | 60 | 80 | 80 | 90 | 100 | 201087 | 201636 |
| fmtlog | 29 | 29 | 39 | 39 | 39 | 79 | 100663 | 103036 |
| binlog | 39 | 49 | 49 | 59 | 59 | 69 | 114607 | 118427 |
8-thread results:
| Library/Quantile Time (ns) | 0th | 50th | 75th | 90th | 95th | 99th | 99.999th | 100th |
|---|---|---|---|---|---|---|---|---|
| Quill | 30 | 70 | 80 | 90 | 120 | 160 | 387276 | 387911 |
| fmtlog | 29 | 69 | 79 | 109 | 129 | 179 | 190420 | 192421 |
| binlog | 40 | 50 | 70 | 110 | 120 | 170 | 137961 | 139571 |
Conclusions
The theoretical limit of single-threaded Quill is about the same as binlog, but the actual result is still faster than binlog. But for multithreading, 4-threaded Quill is slightly worse than the new version of binlog, and 8-threaded Quill is about the same as the new version of binlog.
In terms of single-threaded performance, on simple objects, single-threaded performance fmtlog≈Quill>binlog. On complex struct, single-thread performance binlog>fmtlog>Quill, but binlog performs worse at 99.999 and 100th percentile.
Based on the multithread and single-thread results, basically the latency of each of the multithreading results is higher. The performance of multithreading to log the Foo struct is binlog>fmtlog>Quill, but multithreading to log a simple variable is fmtlog>binlog>Quill.
This should be because the Foo struct has an advantage over the binlog, but if you consider more complex scenarios, such as when a user may need to log a struct, a string, or a double, then it is important to look at the performance of a single simple object.
Realizations
Quill:
binlog:
